
Distance Vector Routing Algorithm
Routing algorithms are critical in computer networking, as multiple devices connect with one another to share information. One such technique is the distance vector algorithm, which is used to route data across networks. In this post, we will explore the distance vector routing algorithm. By adopting an example, we will learn how the distance vector routing protocol works and what the benefits and drawbacks of adopting this distance vector method are.
What is a Distance Vector Routing Algorithm?
A distance vector routing algorithm is a sort of routing algorithm that determines the optimum path for data packets to take in a network. The Bellman-Ford method, named after its founders Richard Bellman and Lester Ford Jr., is another name for this method.
Each router in a network maintains a table of distances to all other routers in the network as part of the distance vector routing method. The distance vector is the name given to this table. The distance vector comprises the distance between each router in the network as well as the next hop router to which the data packet should be sent in order to reach its destination.
The distance vector routing algorithm computes the distance vector table using the Bellman-Ford equation. The Bellman-Ford equation considers the cost of the link between the present router and its neighbors, as well as the distance vector between the routers. Based on the information in the distance vector table, the algorithm then chooses the shortest path to the destination router.
The simplicity of the distance vector routing algorithm is one of its key features. It is simple to set up and use, making it a popular choice for small networks. It is, however, less efficient than other routing algorithms, such as the Link State Routing Algorithm, and is more prone to routing loops.
A routing loop occurs when a packet is transmitted in a loop between routers due to the router’s distance vector table not being properly updated. To avoid this, the Distance Vector Routing Algorithm employs a method known as split horizon.
Split horizon prevents a router from sending distance vector information back to the router from which it received it. This eliminates the formation of a loop and guarantees that the distance vector table is accurately updated.
Finally, the distance vector routing technique is a popular routing algorithm that is easy to construct and understand. Each router keeps a table of distances to all other routers in the network and uses the Bellman-Ford equation to compute the shortest path to the target router. It is, however, less efficient than other routing algorithms and is more prone to routing loops. As a result, it is used in local networks rather than huge networks.
Features of Distance Vector Routing Protocol
The distance vector routing protocol has the following characteristics:
- It is distributed in nature, which means that each node gathers information from one or more of its directly connected neighbors, computes it, and then distributes the result to its neighbors.
- It is an iterative process in which neighbors exchange information until no more information is available.
- It is asynchronous because it does not require all of its nodes to operate at the same time.
- It is mostly used in RIP and ARPANET.
- Each router maintains a distance database known as vector.
- Only data sharing between adjacent nodes is possible.
- The routers transfer the information (or notion) of the full autonomous framework.
How Distance Vector Routing Protocol Works
The distance vector routing protocol proceeds as follows:
- Initialization: Each router in the network is setup with its own distance vector table, which lists the distance to each other network in the inter-network (in terms of hop count or other metrics).
- Distance vector table transmission: Each router transmits its distance vector table to its immediate neighbors.
- Distance vectors are updated when a router receives a distance vector from a neighbor by comparing the distance to a network via its neighbor with the distance currently stated in its own database. If the new distance is less than the old one, the router updates its table.
- Calculating best path: Each router calculates the best way to each network using the information in its distance vector table and changes its routing table accordingly.
- Periodic updates: The transmission and updating of distance vectors is done on a regular basis, often every 30 seconds. This enables the network to swiftly adapt to changes in topology.
- Convergence occurs when all routers in the network have the most up-to-date information and have converged in the optimum way to each network.

Example of Distance Vector Routing
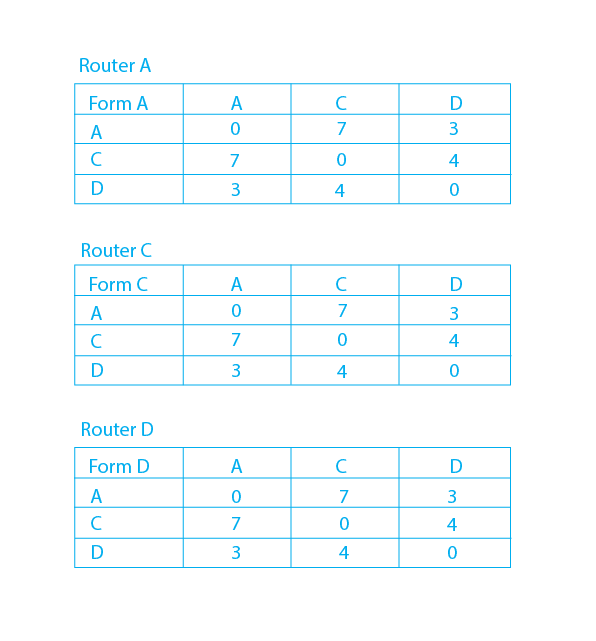
There are three routers in the network depicted below: A, C, and D, with the weights AC =8, CD =4, and DA = 3.
Step 1: In this DVR (Distance Vector Routing) network, each router shares its routing database with every neighbor. For example, A will share its routing table with neighbors C and D, and A will share its routing table with C and D.
Step 2: If the way through a nDVRess is expensive, the router modifies its local table to route packets to the neighbor. The router updates the lower cost for A and C in this table by changing the new weight from 8 to 7 in router A and from 8 to 7 in router C.
Step 3: The complete amended routing table for all routers A, C, and D using the reduced-cost distance vector routing protocol is shown below-
Advantages of Distance Vector Routing Algorithm
In computer networks, the distance vector routing algorithm, often known as the Shortest Path Routing Algorithm, has several advantages:
- Simplicity: The distance vector routing technique is simple to develop and understand, making it suitable for usage in small networks or in areas with limited resources.
- Low overhead: Because routers only communicate information with their local neighbors, the distance vector routing technique has a low overhead. This increases its bandwidth and processing power.
- Flexibility: The distance vector routing algorithm is versatile and can be used with other metrics to find the best path, such as hop count or delay. Scalability: The distance vector routing technique may be readily scaled to suit a growing network by simply adding more routers to the network and updating the distance vectors accordingly.
- Stability: Distance vector routing protocols are less prone to routing loops, which can result from changes in network topology and cause network instability.
Many businesses find distance vector routing protocols like RIP and IGRP to be an appealing alternative because they have extensive support from router suppliers and are compatible with a wide range of network devices.
Limitations of Distance Vector Routing Algorithm
In computer networks, the distance vector routing algorithm, often known as the Shortest Path Routing Algorithm, has several drawbacks:
- Slow convergence: Due to the slow convergence time of distance vector routing protocols, it takes a long time for the network to react to changes in topology. This can result in black holes or routing loops.
- Distance vector routing techniques are vulnerable to the count-to-infinity problem, in which the distance between two routers can grow indefinitely if a link fails. This can make the network untrustworthy.
- Distance vector routing techniques are unsuitable for big networks because they require every router to know the whole routing table, which might result in excessive overhead.
- Limited accuracy: Distance vector routing protocols estimate the best path using only one measure, such as hop count, which might result in inferior routes.
- Security flaws: Distance vector routing protocols lack built-in security mechanisms, making them open to assaults.
- Distance vector routing techniques are not suited for large networks since they rely on frequent updates from all routers, which might generate a significant overhead and will not scale effectively.
Because of these constraints, the distance vector routing method is generally employed in small networks or in locations where resources are restricted and more complex routing protocols such as OSPF and EIGRP are not practical.
Summary
- A dynamic protocol is distance vector routing.
- In computer networks, the distance vector routing algorithm is also known as the Bellman-Ford algorithm or the shortest path routing algorithm.
- The router uses a direct link to deliver information to neighboring nodes.
- The router determines the best route from source to destination.
- On a regular basis, each router in the network exchanges a topology change with a neighboring router.
Reference
- Distance Vector Routing Algorithm – PrepBytes
- Distance Vector Routing (DVR) Protocol
- Computer Network | Distance Vector Routing Algorithm
- Distance Vector Routing Algorithm
FAQs
Here are some frequently asked questions about the distance vector algorithm.
Q1: What is the difference between the distance vector algorithm and the link-state algorithm?
Answer:The distance vector algorithm is a decentralized method that exchanges distance information between network nodes, whereas the link-state algorithm is a centralized algorithm that trades network topology information.
Q2: What is a routing loop?
Answer: When a node receives updates from numerous paths with the same cost, the node transfers data in a loop, repeatedly forwarding it between the same nodes.
Q3: What is the counting-to-infinity problem?
Answer:The counting-to-infinity problem happens in the distance vector routing technique when a node gets updates about a failed path and continues to utilize the same path in its routing database, increasing the distance indefinitely.
Q4: What is the Bellman-Ford algorithm?
Answer: The Bellman-Ford algorithm is a distance vector routing technique that determines the shortest path to all other nodes in the network using a dynamic programming approach.
Q5: How do you prevent routing loops in the distance vector routing algorithm?
Answer: Routing loops in the distance vector routing algorithm can be avoided by employing strategies such as the split horizon, poison reverse, and hold-down timers.
Q6: How do you prevent a counting-to-infinity problem in a distance vector routing algorithm?
Answer: The distance vector algorithm can avoid the counting-to-infinity problem by employing tactics such as route poisoning and triggered updates.
Q7: What is the difference between the distance vector algorithm and the path-vector algorithm?
Answer: The route-vector algorithm calculates the shortest way based on the path vector, which is a sequence of AS numbers, whereas the distance vector algorithm calculates the shortest path based on the cost metric.


